一、 索引优化和语句优化
1. 索引优化
索引是一种数据结构,能加快数据库的查询速度
索引类型包括:聚集索引、覆盖索引、组合索引、前缀索引、唯一索引
默认使用索引:B+树(多路搜索树)结构索引
1.1 执行计划汇中的 type
- system 一个表一条记录
- const 常量匹配,仅匹配一条记录
- eq_ref 唯一性索引扫描 对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
- ref 非唯一性索引扫描 返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。
- range 只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。
- index 全索引扫描
- all 全表扫描
2. 语句优化
- 查询语句不使用 select *
- 查询开销大
- 增加 IO 操作
- 失去“覆盖索引”优化器的可能性
- 可读性差
- 尽量减少子查询,使用关联查询(left join,right join,inner join)替代
- 子查询要查询两次
- 关联查询是先建立临时表,将多个表关联起来,再查询一次,效率要比子查询高
- 减少使用IN 或者 NOT IN,使用 exist,not exist 或者关联查询语句代替
- IN 或 NOT IN 适合子表数据比较小,exist 和 not exist 适合子表数据比较大
- IN 和 NO INT 是先对两个表缓存数据,再笛卡尔积查询,属于内存查询
- exist 和 not exist 是查询数据库消耗性能更高
- or 的查询尽量用 union 或者 union all代替,union all有重复情况,union 会消除重复情况
- or 查询时,查询条件出现非索引列,存在索引的查询列会失效
- 使用 union 有索引列的用索引查询,没有索引列的 正常查询
- 尽量避免在 where 子句中使用 != 或 <> 操作符,否则将 引擎放弃使用索引而进行全表扫描
- 尽量避免在where 字句中对 字段进行 null 值判断,否则将导致 引擎放弃索引进行全表扫描
2.1 多表优化
- 小表驱动大表,效率要比大表驱动小表高
- 频繁查询的字段加上索引
2.2 避免索引失效
- 复合索引,不要跨列或无序使用
- 复合索引,尽量使用全索引匹配
- 对索引进行函数、计算、类型转换
- 复合索引不能使用不等于 (!= <>) 或 is null (is not null) ,否则自身以及右侧全部索引失效
- 使用索引范围查询有sql优化器干预,索引有概率失效,尽量使用索引覆盖
- like 尽量以常量开头不要以 ‘%’开头,否则索引失效
- 尽量不要使用or ,否则索引失效
3. 其他优化
3.1 exist 和 in
- 如果主查询的数据集大,则使用In
- 如果子查询的数据集大,则使用exist
exist 语法:将主查询查询的结果,放到子查询结果中进行条件校验,看子查询中是否有数据,如果有数据,则校验成功
如果符合校验,则保留数据
in 语法:先子查询,然后结果给主查询,子查询会缓存起来
3.2 order by
using filesort 有两种算法:双路排序、单路排序(根据 IO 次数)
- MySQL 4.1之前 默认使用 双路排序:双路:扫描2次磁盘(1:从磁盘读取排序字段,对排序进行排序 2:扫描其他字段)
—— IO 较消耗性能
- MySQL 4.1 之后 默认使用 单路排序:只读取一次(全部字段),在buffer 中进行排序。但此种单路排序会有一定隐患(不一定真的是“单路 | 一次IO”,有可能对次)
注意:单路排序比双路排序占用更多的buffer
单路排序在使用时,如果数据量大,可以考虑调大 buffer 的容量大小:set max_length_for_sort_data = 1024
如果 max_length_for_sort_data 值太低,则 mysql 会自动从 单路->双路 (太低:需要排序的列的总大小超过了 max_length_for_sort_data 定义的字节数)
原因:如果数据量特别大,则无法 将所有字段的数据 一次性读取完毕,因此会进行 “分片读取、多次读取”
提高 order by 查询的策略:
- 选择使用单路、双路,调整buffer 的容量大小
- 避免select * …
- 复合索引 不要跨列使用,出现 using filesort
二、锁和死锁
1. 锁:
乐观锁:通过版本号控制,查询时获取版本号,提交时比较版本号
悲观锁:基于数据库的锁机制,真正保证数据访问的排他性
1.1 造成死锁的必要条件:
- 互斥条件
- 请求与保持
- 不剥夺条件
- 循环等待
1.2 锁升级
锁升级也是跟索引挂钩的,InnoDB 是使用的行锁,但在操作时很容易升级为表锁
- InnoDB 的行锁是加在索引上的,操作不走锁引,也就是 where 条件不是索引列,则会升级锁
- 有索引查询,说明要操作的数据在索引上已经确定了,只要锁住 索引条件的记录,加行锁
- 无索引查询,说明是要全表查询,并不能保证要查询的记录有其他事务要去操作,所以升级为表锁
- 非唯一索引记录超过一定数量时,查询语句优化时会选择不走索引,从而造成索引失效,行锁也会升级为表锁
1.3 解决死锁:
- 查询时使用索引条件,避免因查询优化导致锁失效或不使用索引条件查询,从而出现锁升级为表锁
- 合理设计索引,行锁都是加在索引上的,尽量缩小锁的范围
- 尽可能使用低级别的事务隔离机制
- 尽量减少查询条件的范围,尽量避免间隙锁或缩小间隙锁的范围
- 设置按照同一顺序访问资源,类似于串行执行
2. 表锁的操作
mysql 要使用表锁,mysql 引擎 Myisam 使用的就是 表锁,但不支持事务,没有提交这说法
2.1 查看加锁的表
1 | show open tables; |
2.2 加读锁
- 当前session回话:
1 | lock table tablelock read; |
1 | ERROR 1099 (HY000): Table 'tablelock' was locked with a READ lock and can't be updated |
1 | select count(1) emp; -- 不允许 |
1 | ERROR 1100 (HY000): Table 'emp' was not locked with LOCK TABLES |
- 其他session会话:
1 | select * from tablelock; -- 读(查)允许 |
1 | select * from dept; -- 读允许 |
总结:
- 获得读锁的会话只能对锁本身的表可以读操作,不允许写操作
- 获得锁的会话不允许对其他表读写操作
- 其他会话对锁本身的表可以读操作,写等待
- 其他会话对其他表可以读写操作
2,.3 加写锁
当前会话:
1 | lock table tablelock write; |
1 | select * from dept; -- 读不允许 |
1 | ERROR 1100 (HY000): Table 'dept' was not locked with LOCK TABLES |
其他会话:
1 | select * from tablelock; -- 读等待 |
1 | select * from dept; -- 读允许 |
总结:
- 获得读锁的会话只能对锁本身的表读写操作
- 获得锁的会话不允许对其他表读写操作
- 其他会话对锁本身的表读写等待
- 其他会话对其他表可以读写操作
2.4 释放锁
1 | unlock tables; |
2.5 分析表锁定
分析表锁定严重程度:
1 | show status like 'table%'; |
1 | +----------------------------+-------+ |
官方文档:https://dev.mysql.com/doc/refman/8.0/en/server-status-variables.html
一般建议:Table_locks_immediate / Table_locks_waited > 5000,建议采用 InnoDB 引擎,否则 MyISAM 引擎
3. 行锁的操作
mysql 默认使用 InnoDB 引擎,而InnoDB 使用的是行锁,事务默认会自动提交,分析行锁,需要关闭自动提交
1 | set autocommit=0; |
3.1 读操作
1 | select * from linelock; |
一个会话关联一个事务,也就是说,打开了一个会话窗口,就是开启了一个事务
- 其他事务在该事务期间提交的数据都是不可见的,这就是事务默认级别的可重复读,就是会读到历史记录
3.2 写操作
当前会话:
1 | insert into linelock(name) values('7a'); -- 写操作 |
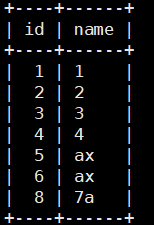
其他会话:
1 | select * from linelock; -- 允许读操作 |
注意:读当前会话刚插入的数据时其他会话是不可见的,因为未提交
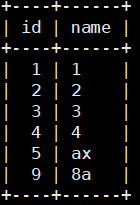
1 | update linelock set name='77' where id = 8; -- 行上锁,等待写操作,直到当前会话commit/rollback |
总结(默认可重复读级别):
- 当前会话读操作,不会出现脏读和不可重复读,可能导致读取到历史记录
- 当前会话写操作,其他会话写等待,会出现丢失更新(回滚/覆盖)、幻读
- select 就是快照读,快照读不加锁,不会产生幻读,MVCC 机制
- select for update、insert、update、delete 都是当前读,当前读会产生幻读,数据库角度不会产生丢失更新,应用逻辑会产生丢失更新
- 可重复读级别下,两个事务同时查询一条数据,第一个事务先更新并提交,第二个事务由于是快照读,会读到历史数据,但更新是属于当前读,更新条件是当前最新数据,所以更新失败
- 可重复读级别下,两个事务同时查询一条数据,两个事务同时更新该数据,后更新的数据会阻塞,直到先更新的事务提交,后一个事务才会更新,但后提交的事务由于发生阻塞,又因为更新是当前读,所以更新条件是当前最新数据,更新失败
3.3 查询行锁
将自动提交关闭
1 | -- 第一种 方法 |
通过 for update 给查询 加行锁
1 | select * from linklock where id = 2 for update; |
总结:
- 如果查询的数据时通过 id很明确的,则使用的是 行锁
- 如果查询条件不包含主键也不明确,这个时候会锁住整个表,使用的是 next-lock (行锁 + 间隙锁)
另外补充: update、insert、delete 这种操作 也是使用了 next-lock 机制
next-lock 机制 只会 让写操作 锁住整个表,对于 读操作不影响
3.4 分析行锁
行锁分析:
1 | show status like '%innodb_row_lock%'; |
1 | +-------------------------------+--------+ |
4. 可重复读原理
用到的原理就是 MVCC (多版本并发控制机制)
关于 readView、undo log、redo log
undo log 包含两个隐含域:事务id和回滚point(指向undo log),是一种链表的数据结构
readView 包含一个事务数组、最大事务id、最小事务id、当前事务id
如果 trx_id < min_trx_id,则说明该版本对于当前事务(read view)来说,是已提交事务生成的,那么对于当前事务可见。
如果trx_id >= max_trx_id:则说明该版本对于当前事务(read view)来说,是”将来”的事务生成的,那么对于当前事务不可见。
如果min_trx_id <= trx_id < max_trx_id:
- 如果trx_id在read view的活跃事务id列表中,则说明该版本对于当前事务(read view)来说,是已开始但未提交的事务生成的,那么对于当前事务不可见。
- 如果trx_id不在read view的活跃事务id列表中,则说明该版本对于当前事务(read view)来说,是已提交的事务生成的,那么对于当前事务可见。
三、 慢查询日志和海量数据分析
MySQL提供一种日志记录,用于记录MYSQL 响应时间超过阈值的SQL 语句 (slow_query_log)
1. 慢查询日志:
慢查询日志默认关闭,建议:开发调优时打开,最终部署时关闭
1.1 开启慢查询日志:
检查是否开启了 慢查询日志:show variables like ‘slow_query_log’
临时开启:set global slow_query_log = 1
永久开启:/etc/my.cnf 中追加配置:
1 | vim /etc/my.cnf |
1.2 设置慢查询阈值:
- 临时设置阈值:set global long_query_time=5
- 永久设置阈值:/etc/my.cnf 中追加配置:
1 | vim /etc/my.cnf |
1.3 查询超过阈值sql
查询超过阈值的SQL数:show global status like ‘%slow_queries%’;
查询慢查询的sql:
- cat /var/lib/mysql/localhost-slow.log
- 通过mysqldumpslow工具查询慢sql
- s:排序方式
- r:逆序
- l:锁定时间
- g:正则匹配模式
1 | -- 获取返回记录最多的 3 个sql |
2. 海量数据分析
2.1 解决开启过程函数与慢查询日志冲突:
临时解决:set global log_bin_trust_function_creators=1
永久解决:/etc/my.cnf 中追加配置:
1 | vim /etc/my.cnf |
2.2 使用存储过程插入海量元素:
1 | create table dept |
2.3 分析海量数据:profiles
show variables like ‘%profiling%’;
set profiling = on
(1)profiles
show profiles; – 记录所有 profiling 打开之后的, 全部SQL 查询语句所花费的时间
(2)精确分析:sql诊断
1 | show profile all for query [上一步查询的 Query_id] |
(3)全局查询日志:记录开启之后的 全部 Sql 语句
全局的记录操作 ,仅仅在调优、开发过程中打开,部署一定关闭
show variables like ‘%general_log%’
- 全局日志保存到表:
1 | set global general_log = 1 -- 开启全局日志 |
开启后,会被记录到 mysql_general_log 表中
- 全局日志保存:
1 | set global general_log = 1 -- 开启全局日志 |
开启后,会被记录到文件/tmp/general.log中

