创作宗旨:化繁为简,绝不冗余,点到为止
ConcurrentHashMap<K,V> 继承了AbstractMap<K,V>,实现了ConcurrentMap<K,V>和Serializable。
说明:AbstractMap<K,V>实现了基本的Map操作ConcurrentMap<K,V>规范了对k-v的并发操作的方法
一、介绍
ConCurrentHashMap是如何做到线程安全的?
通俗来讲,ConcurrentHashMap<K,V>已经迭代了几个版本,我们先从JDK7说起,起初为了实现了对HashMap真正意义上的并发,在ConcurrentHashMap<K,V>引入了一个静态内部类Segment(段),而且ConcurrentHashMap<K,V>也聚合了一个Segment的成员变量数组来维护,每一个Segment数组的下标元素相当于一个HashMap,也就是一个HashEntry数组+ 每位下标元素构成一个HashEntry链的头结点(依旧保存值),每次存在线程安全的操作都会去使用该数组的其中一个下标,并锁住该下标(其他线程无法访问),而不同[下标之间的操作是不会相互影响的,也就不存在冲突的情况。Segment继承了ReentrantLock(可重入锁),用法其实用到加锁和解锁,保证每一个线程使用前加锁,使用完成后释放锁。ConcurrentHashMap中Segment与Entries的示意图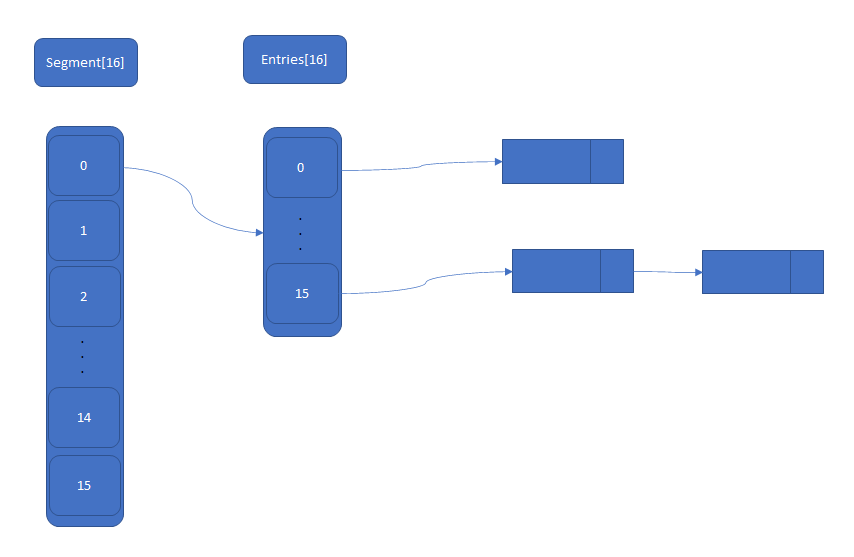
更专业来讲,ConcurrentHashMap使用了分段锁Segment来解决线程安全。2. JDK7 的 get 和 put 以及扩容
- get
get操作没有任何加锁,所以在ConCurrent是非常高效的。就算获取1
2
3
4
5
6static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}key之前value被改变了,由于volatile修饰了value变量,所以对内容是及时更新的,新增和删除操作亦是如此。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// Concurrent 初始化时会初始 Segment数组和 第 0 位下标即Segment[0](包括 HashEntry数组 的初始化)
// 如果 segment 对应的 HashEntry 数组不为空,则往下遍历
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 遍历 HashEntry 数组 哈希命中的下标元素(链表)
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
// 如果找到了 key就返回对应的value,否则往下继续遍历链表
// 这里前面匹配的是 基本数据类型,
//如果是 复杂对象,则使用的是先 hash筛选桶下标,相等再去 比较 “值”
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
} - post
在ConcurrentHashMap中post操作是不允许设置value为null。Concurrent初始化时会初始Segment数组和 第0位下标即Segment[0](其中包括HashEntry数组的初始化),所以这里会出现命中到另外15个未初始化的Segment锁段,即当前Segment为null的情况1
2
3
4
5
6
7
8
9
10
11
12
13
14public V put(K key, V value) {
Segment<K,V> s;
// 不允许对 value 设置为 null
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
// 没有找到,即说明未初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 初始化当前 Segment 对应的 HashEntry 数组
s = ensureSegment(j);
return s.put(key, hash, value, false);
}post细节1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 尝试加锁
HashEntry<K,V> node = tryLock() ? null :
// 如果不成功, 进入 scanAndLockForPut 流程
// 如果是多核 cpu 最多 tryLock 64 次, 进入 lock 流程
// 在尝试期间, 还可以顺便看该节点在链表中有没有, 如果没有顺便创建出来
scanAndLockForPut(key, hash, value);
// 执行到这里 segment 已经被成功加锁, 可以安全执行
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 更新
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 新增
// 1) 之前等待锁时, node 已经被创建, next 指向链表头
if (node != null)
node.setNext(first);
else
// 2) 创建新 node
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 3) 扩容
// 必须 是 达到阈值 并且 HashEntry 数组还没被扩容,也就是长度依旧是旧值
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// tab已更新,即扩容已经完毕,将 node 作为链表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
} - 扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62private void rehash(HashEntry<K,V> node) {
// 每个 Segment 对应的一个 HashEntry<K,V>数组
HashEntry<K,V>[] oldTable = table;
// 扩容前 HashEntry<K,V>数组的长度
int oldCapacity = oldTable.length;
// 扩容后 HashEntry<K,V>数组的长度 = 扩容前 HashEntry<K,V>数组的长度 * 2
int newCapacity = oldCapacity << 1;
// 扩容阈值的元素数量,HashEntry<K,V>数组 中元素的个数到 某个数量(低于最大数)时的数量
threshold = (int)(newCapacity * loadFactor);
// 初始化一个新的 HashEntry 数组,每个下标表示的 HashEntry 都为 null,后面会用到这个 null 做头插法 put 元素
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// hash 命中 & 操作要用的掩码(计算hash结果的长度)
int sizeMask = newCapacity - 1;
// 遍历 扩容前 HashEntry<K,V>数组
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
// 当前 HashEntry<K,V>数组 下标只有一个元素,则直接赋值给 新数组对应下标
// 这里对应的新的下标跟 原下标已经不一样了,因为是按照 扩容后 的长度来计算得到的
if (next == null) // Single node on list
newTable[idx] = e;
// 如果链表长度 大于等于两个元素以上
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 重用 链表最后面 新命中值 相同的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 将重用的链表头结点 转移到 新的 数组中
newTable[lastIdx] = lastRun;
// Clone remaining nodes
// 链表剩下的 部分,挨个按照头插法 命中到 新的数组中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 最后再 把要 put 的值 头插法 加入到 新的数组中
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// 这里通过 暂时 数组操作完毕再 赋值,能够避免操作中途 被其他 线程再次重复操作
// 在这之前 其他 线程无法进入
// 一赋值 其他线程 就算判断 达到阈值,但newTable 的大小改变
// tab.length < MAXIMUM_CAPACITY 也会让 其他线程直接去 新的数组 put 操作
table = newTable;
}JDK8抛弃了Segment分段锁,转而使用CAS+synchronized来保证并发安全性。
并且,不再单纯使用链表,JDK8在HashEntry数组中的链表长度大于8的时候会去转化为红黑树结构。
在这里,链表长度大于8时,才会去进一步判断阈值是否达到。
与JDK7扩容的区别在上一篇 深入浅出~HashMap的底层原理透析 详细讲过了,其实与ConCurrentHashMap大同小异,也就是多做了CAS的操作、链表转化红黑树和等待的put会帮忙扩容。二、附语
谢谢大家,我会继续努力,只为力争创作高质量的文章,分享给各位有需要的读者。
你们的阅读和评论是对作者最大的支持!
我的技术专栏:https://github.com/fyupeng
专注品质,热爱生活。
交流技术,寻求同志。

