创作宗旨:化繁为简,绝不冗余,点到为止
直接开门见山,就事论事!
什么是 HashMap?
HashMap类继承了父类AbstractMap<K,V>,实现了接口Map<K,V>, Cloneable, Serializable,AbstractMap<K,V>实现了对Map的基本操作,Serializable是序列化接口,可实现序列化,Map<K,V>接口规范了k-v对操作的抽象方法,Cloneable规范了继承了Object后去使用clone()方法前必须得实现Cloneable接口,否则抛出CloneNotSupportedException错误。
一、介绍
1. HashMap 的线程不安全的场景
- 死锁
扩容产生死锁的原因关键有两点:
第一点:链表的头插法转移结点,JDK8版本就改成了尾插法;
第二点:多线程环境下,CPU的让出使得头结点的指针指向发生变化,但原线程重新占有CPU时仍然采取原先的做法;
解读:JDK8下使用尾插法,就算头结点已经转移了,但还是在头结点位置,也就是转移前后链表顺序不改变,只是多了一次重复的操作,结果不影响。
我不会用篇幅很长而做这么点事情,没必要,很简单的事 5 幅图就可以啦。
由于HashMap是数组+链表的数据结构,旧桶是指数组下标所在位置。线程 1 扩容操作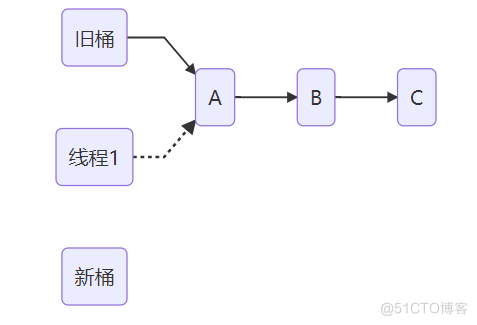
线程 1 转移结点A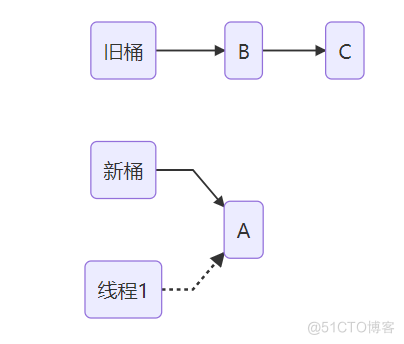
线程1结点转移完毕
线程2开始转移结点A
因为是线程2首先要扩容的,不过CPU时间却让给了线程2,线程2也发觉需要扩容,等扩容完毕后再把CPU还给线程1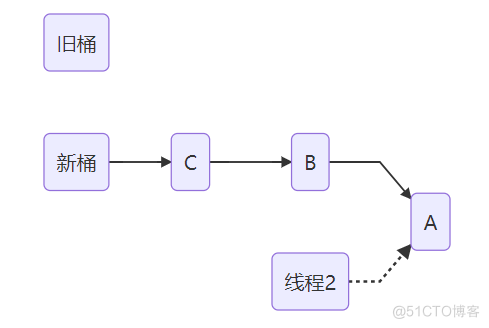
线程2转移结点A结束,环形链产生,也就是产生死锁。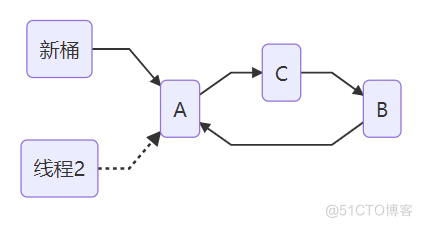
所以原因的头插法得以佐证,CPU的轮询切换也演绎的很到位。
线程不安全讲完,下面就将原理,去潜移默化它。
2. HashMap 实现哈希命中均匀
哈希也就是k的hashcode计算后得到的下标,而hashcode是一个32位的int类型,要让分布均匀,即让不同的k不能出现有相同的效果,也就是得有唯一性,就要完全去利用高16位和低16位,而如果直接用32位去取模运算,高16就可能会用不到,导致hashcode高16位不同的k依旧命中同一个桶位。
所以JDK8采取的做法是对高16位与低16位进行异或运算,这样就变相保留了高位和低位的所有特征了。
哈希均匀,JDK8之后
1 | return (key == null) ? h = key.hashCode() ^ (h >>> 16); |
取模运算,JDK7之前
1 | h & (length - 1) |
3. HashMap 参数以及扩容机制
初始容量16,达到阈值扩容,阈值等于最大容量 * 负载因子,扩容每次2倍,总是2的n次方。
- 扩容机制
使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组元素拷贝到新的Entry数组里,Java1.7重新计算每个元素在数组中的位置。
而Java1.8它不需要重新计算每个元素,它会先比较元素的hashcode & 原来数组的大小的结果,如果为0,就以元素的原下标加入到新数组中,如果为1,就在原下标加上原数组的大小加入到新数组中,这样这两种情况就命中到新数组的前一半和后一半了,也就是将原本全在原数组大小的所有元素又均匀分布一些元素到扩容未使用的下标中。
那么就解释一下,假设加入的元素是随机的,也就是所有情况的hash值是均等出现的,而&原数组大小可以这样比如,有64个元素均等的从0到63,那么0到15分配给了扩容后数组大小为32的左半部分,16-31分配给了右半部分,32-48分配给了左半部分,48-63分配给了右半部分,就比较均匀分散在了两侧,而且机会均等,很巧妙!
1 | // 分布到左侧 |
4. HashMap 的 get 和 put 操作
- get
让我们见识下此时无图胜有图的效果吧!
get由源码解读是先获取key的hashCode,然后定位到对应的数组位置,再去遍历该元素处的链表
在这里才讲equals我觉得是最合适的,可以区分它与hashCode的区别,如果hashCode相同的两个元素在同一个数组下标,equals就开始发挥作用了,
不得不说,当然别说我是话痨,我觉得HashMap加入这两个的初衷是如果在一个庞大的Map中,要去get某一个key的value,有一种最直接的做法,就是直接整个Map去equals比较,这没错,而且还是有用的,但加入hashCode之后,hashCode能够给equals先筛选一番,因为不同的key,它的hash值一般是不同的,理解这里的一般,所以hash值不同的equals肯定就不同,就没必要再去对不同下标元素来equals比较了,好理解吧!
由于HashMap中新加入了红黑树,就多了一种get到key的方法,是一种二分法,对于大量数据的链表是不推荐的,所以采用红黑树(总是平衡的二叉树)更加地高效!
- put
put的实现主要针对两种key,一种是不存在的key,一种是已存在的key
局部源码
1 | public V put(K key, V value) { |
1 | static final int hash(Object key) { |
如果为前者,而且key值为null,就在数组下标为0的链表中去寻找key为null的值,当然找不到,就创建key为null的结点。
如果为前者,而且key值不为null,就调用该元素hash计算具体的下标,在该下标的链表中寻找,当然也寻找不到,就尾插法加入该k-v结点。
如果为后者,即找到了,直接赋值就可以了,不需要考虑是否为null。
这里要分开来put是因为,在HashTable上,是不允许有key为null的情况出现,因为当key为null时,key.hashCode()会报空指针异常。
所以在HashMap做了特别的处理,对key为null做了单独处理,这样就解决了key为null的情况。
还有一点,HashMap的value如果设置为null,虽然你put了,但再去取key的时候,依旧是不存在!
二、附语
不足之处请大佬予以佐证,不希望哪个地方出现的错误误导同行,结果闹出笑话来,总之你们的阅读和评论是对作者最大的支持!
谢谢大家,我会继续努力,只为力争创作高质量的文章,分享给各位有需要的读者。
我的技术专栏:https://github.com/fyupeng
专注品质,热爱生活。
交流技术,寻求同志。

